 Click to zoom
Click to zoom
Overview: What DeepSeek V3.2 Means for the AI Race
DeepSeek, a Hangzhou-based team, quietly dropped two models — DeepSeek‑V3.2 and DeepSeek‑V3.2‑Speciale — that claim to sit shoulder-to-shoulder with proprietary heavyweights like GPT‑5 and Gemini 3 Pro. The kicker: both are released under an MIT license with full weights and docs on Hugging Face, so researchers and engineers can actually download, run, and tweak them. That’s a big deal — not just technically but strategically.
How does DeepSeek achieve similar performance at lower cost?
The short answer: a blend of architecture and training choices that prioritize long-range efficiency. DeepSeek’s headline innovation is DeepSeek Sparse Attention (DSA) — a memory-efficient attention variant and what they call a "lightning indexer" that prunes irrelevant tokens and selectively attends across huge windows. Dense attention scales quadratically; DSA aims to avoid that blow-up so 128k token windows aren’t a budget showstopper.
Why sparse attention matters
Practically, this means the model can:
- Handle long documents, books, and codebases — yes, 128k token windows are in scope — without exploding compute costs.
- Keep accuracy on deep reasoning and math benchmarks while doing far fewer FLOPs than a dense approach.
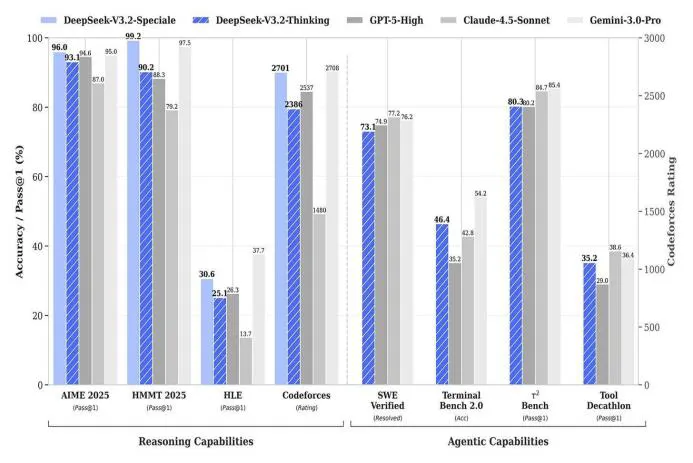
Benchmark and contest performance: Do the claims hold up?
DeepSeek published benchmark runs and contest-style evaluations that suggest parity with some top proprietary systems — especially the Speciale variant, which they tuned for tougher reasoning tasks.
- V3.2‑Speciale reportedly performed extremely well on competition-style tasks (DeepSeek claims gold-level performance on certain math contests and high placements at ICPC-style events). They emphasize contest rules were followed — no external tool shortcuts.
- On coding and math suites (AIME, HMMT, TerminalBench and others) DeepSeek often lands within a few percentage points of GPT‑5‑High and Gemini 3 Pro; in some tool-heavy workflows it even edges them out.
That sounds great — but take a breath. Benchmarking is finicky: prompting, chain-of-thought strategies, verifier pipelines, and decoding settings move numbers around. In my experience reproductions and independent labs will be decisive. If you want to dig in, see DeepSeek's technical report on Hugging Face: technical report (PDF).
Tool use and multi-step reasoning: What's new?
Where they’ve clearly focused effort is in persistent, multi-step tool-enabled reasoning. The model keeps an internal trace across tool calls — web searches, runtimes, notebooks — instead of losing track and re-deriving state each time. DeepSeek trained on a large synthetic pipeline (tens of thousands of complex instructions across many simulated environments) so the model learns to plan, call tools, and fold results back into its reasoning.
An illustrative example (hypothetical)
Picture planning a tight three-day trip from Hangzhou with budget ceilings, hotel-rating constraints, and per-attraction cost tradeoffs that change depending on lodging. The pipeline trains the model to:
- Search multiple pages for prices,
- compute tradeoffs across alternatives, and
- produce a final plan that respects budget and time constraints.
That kind of combinatorial, tool-driven reasoning is where maintaining a reasoning trace matters — you don’t want the model to forget earlier constraints after each web call. This is the difference between a useful assistant and one that keeps repeating itself.
Open sourcing frontier models: business and strategic impact
Releasing frontier models under an MIT license is disruptive in the best and messiest ways. For enterprises and researchers it means:
- Practical self-hosting — you can run DeepSeek V3.2 locally on GPU in 2025 or on cloud instances and dramatically lower per-token spend compared with managed APIs. Learn more about comparable regional lab and enterprise moves in our piece on Why DeepMind’s Singapore AI Lab Rewrites the Asia‑Pacific Playbook.
- Easy fine-tuning and forks — best practices to fine-tune DeepSeek V3.2 Speciale are already emerging from the community.
- Rapid innovation from integrations and bespoke toolchains — because the weights are open, you can build customized pipelines for long-context tasks like legal review or codebase analysis.
But open weights also invite headaches: IP questions, model misuse, and governance challenges. And yes — regulators are watching closely.
Regulatory and geopolitical headwinds
Several governments and agencies have expressed caution:
- German authorities flagged possible unlawful personal-data transfers and urged platforms to consider blocking the app.
- Italy and other EU bodies have taken steps to restrict access, and U.S. policymakers are debating limits on government use of services with certain origins.
Export controls on advanced Nvidia GPUs complicate training and deployment narratives. DeepSeek says they trained on older H800 hardware and supports inference on Chinese chips (Huawei, Cambricon). Whether Huawei/Cambricon ecosystems can scale to training runs comparable to top-tier Nvidia clusters is an open technical and policy question — and one worth watching in coverage about Nvidia export controls and China’s chip ambitions.
Costs and pricing: How much cheaper is DeepSeek?
DeepSeek published per-token pricing that is a fraction of many commercial APIs: some public tiers show roughly $0.28 input / $0.42 output per 1M tokens for V3.2 in certain configurations. If those numbers hold up in real-world deployments, they translate to meaningful savings for long-context workflows — legal document review, long-form research synthesis, and bulk code analysis become cheaper to run at scale.
Limitations and where DeepSeek still trails
Their own report is candid about gaps:
- World-knowledge breadth: V3.2 trails some closed models on the breadth of up-to-date facts — newsy recall and fresh named-entity knowledge can lag.
- Token efficiency: Sometimes DeepSeek needs longer generation trajectories to match the crispness of closed models, which reduces efficiency in short-prompt scenarios.
- Compliance and adoption: Highly regulated sectors may be hesitant to adopt models from certain jurisdictions, at least until governance and compliance checklists are clear.
Why this matters: short- and long-term implications
This release matters for three practical reasons:
- Democratization: Open weights at near-frontier quality let more teams experiment without paywalls — helpful for independent labs and startups.
- Market pressure: Lower-cost, capable open models force cloud and API vendors to justify premium fees with clear enterprise value (SLAs, freshness, safety).
- Policy debate: The availability of high-capability open models sharpens export-control and supply-chain conversations — governments will need clearer rules on risk and access.
From experience, the first months after an open frontier release are noisy and decisive: independent benchmarks, community reproductions, and production integrations will either validate or temper the initial hype. Expect multiple replication attempts — including guides on how to reproduce DeepSeek benchmarks and contest results — over the coming weeks. For hands-on reproduction tips, see our guide on gpt-realtime & Realtime API which covers practical reproducible pipelines (note: not the same model but the article discusses reproducible experiment patterns and tool integration best practices).
Where to learn more (sources & further reading)
- DeepSeek model hub and technical assets: V3.2 on Hugging Face and technical report (PDF).
- OpenAI GPT‑5 announcement and capabilities: OpenAI — GPT‑5.
- Google Gemini 3 announcement: Google — Gemini 3.
- Reporting on regulation and export controls: look for Reuters and CNBC pieces on Nvidia export limits and policy responses.
Final thoughts: a moment to watch closely
- Frontier reasoning models 2025: V3.2 and the Speciale variant show competitive performance on math, coding, and reasoning benchmarks.
- Huge cost savings: DeepSeek reports inference cost reductions that make long-context workloads far cheaper than many cloud APIs.
- Open weights, MIT licensed LLM: Full model weights and examples on Hugging Face lower the bar for experimentation and self-hosting.
- Regulatory friction: Europe and parts of the U.S. are already raising data-residency and security flags; some platforms and jurisdictions have moved to restrict access.
DeepSeek V3.2 is one of those moments that forces everyone to rethink assumptions: open-source alternatives to GPT-5-level systems, delivered with long-context tricks like sparse attention, and shipped under permissive licensing. It's exciting — and a little unnerving. Expect forks, fine-tunes, and real-world tests; and expect regulators and enterprises to respond cautiously. I’ll be watching independent evaluations and community replications closely — that’s where the story clarifies itself.
Quick note — this synthesis pulls from DeepSeek’s public materials, published benchmarks, and contemporary reporting. For reproduction tips and deeper technical detail, consult their Hugging Face pages and linked paper.
Thanks for reading!
If you found this article helpful, share it with others